
Chyba każdy internauta kojarzy sytuację, w której przed zarejestrowaniem się w danym serwisie, wysłaniem komentarza lub uzupełnieniem formularza, musiał udowodnić, że jest człowiekiem i wpisać w konkretnym miejscu wyświetlane na obrazku cyfry, litery lub wyrazy.
CAPTCHA to skrót od Completely Automated Public Turing test to tell Computers and Humans Apart. Oznacza to rodzaj testu, który ma nie być trudny do rozwiązania przez człowieka, ale skomplikowany dla maszyny. Dzięki temu można się zabezpieczyć przed botami masowo spamującymi w komentarzach lub zakładających fałszywe konta, bez nadmiernego utrudniania części funkcjonalnej serwisu dla użytkownika. Wraz ze wzrastającą mocą obliczeniową komputerów, nowymi algorytmami oraz możliwością wykorzystania uczenia maszynowego, a dokładnie deep learningu, CAPTCHA staję się coraz łatwiejsze do obejścia przez „maszyny”, co skutkuje podniesieniem poprzeczki, którą odczuje także zwykły użytkownik. Chyba każdemu zdarzyło się być pewnym poprawności wpisywanych liter, a jednak nie przejść testu.
Jak pokazują w swojej pracy badacze z Lancaster University oraz Peking University[1] algorytmy są obecnie tak dobre, że niejednokrotnie przewyższają człowieka w zdolności „domyślania się” jaki konkretnie znak lub słowo kryje się w obrazku CAPTCHA. Metody z jakich korzysta się przy utrudnianiu odczytania znaku to m.in. zachodzenie na siebie (na poniższym obrazku – overlapped), rotacja (rotated), zniekształcanie (distorted) czy stosowanie „fal” w tekście (waved). Oczywiście można stosować również kombinacje powyższych, a także złożone tło (zawierające kropki i kreski), co znacząco utrudnia odczytanie właściwych znaków (zarówno dla algorytmu, jak i człowieka).

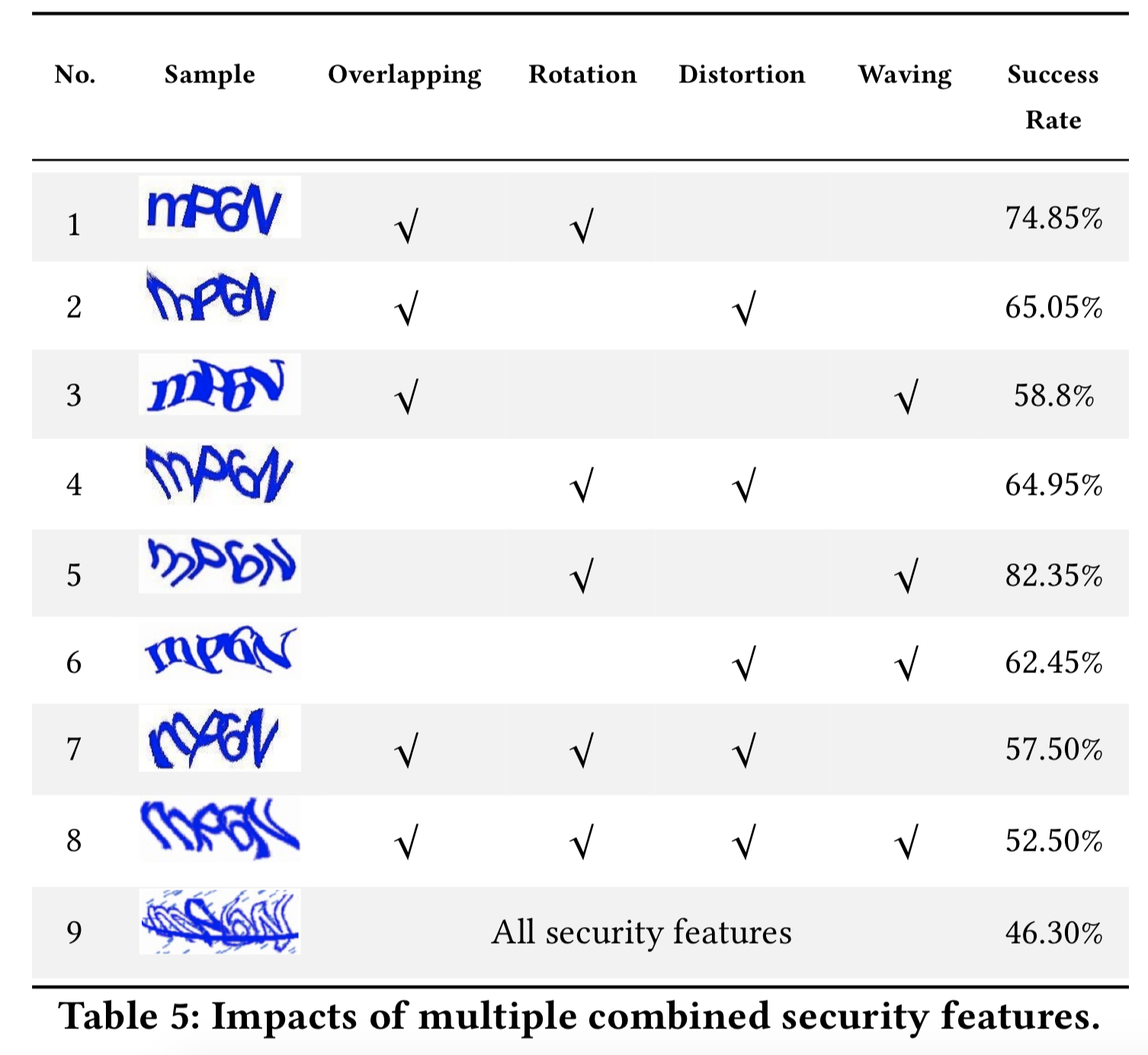
Skuteczność w omijaniu tego typu zabezpieczeń przez algorytmy jest bardzo wysoka. Wykorzystanie wszystkich utrudnień powoduje, że algorytmy odnoszą sukces w około 46% przypadków. Będąc jednak zupełnie szczerym – kiedy muszę odczytać cokolwiek z obrazka takiego jak ten ostatni, to czasami udaje się to dopiero za 2 lub 3 podejściem i myślę, że nie jestem jedyną osobą, której tak zakodowane symbole sprawiają trudność w odczytaniu. Z tej perspektywy 46% to całkiem dobry wynik.
Badacze przeprowadzili w tej kwestii dość dokładne pomiary, z których wynika, że algorytmy już teraz uzyskują lepsze wyniki, lub są minimalnie gorsze od rezultatów osiąganych przez człowieka.

Zastosowana przez badaczy metoda nosi nazwę GAN (Generative Adversarial Network) i w bardzo krótkim czasie (0,05 sekundy) potrafi rozwiązać zagadkę, której do tej pory mógł sprostać jedynie człowiek. Opiera się ona w głównej mierze na wspomnianym wcześniej uczeniem głębokim (deep learning). Nauka polega w tym przypadku na analizowaniu prawdziwych kodów CAPTCHA i próbie ich reprodukcji (oddzielnie szumów utrudniających odczytanie i samego tekstu). W ten sposób GAN będzie w stanie łatwiej usuwać zniekształcenia w kolejnych obrazkach. Powstałe w ten sposób “syntetyczne” kody CAPTCHA (zarówno szum, jak i właściwy tekst) są wykorzystywane do nauki algorytmu (base solver).
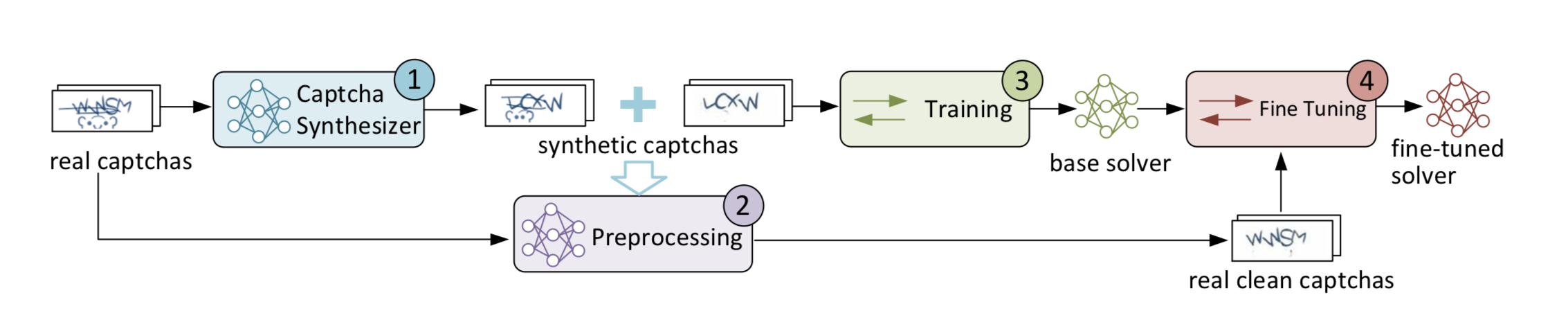
Odkrywcy nowej metody zwracają w swoim raporcie uwagę na fakt, że obecne algorytmy oparte o różne formy uczenia maszynowego pozwalają na znaczne szybsze obchodzenie zabezpieczeń takich jak CAPTCHA. Jednym z rozwiązań może być zastosowanie dodatkowych zmiennych, które pozwolą wykluczyć udział bota np. aktywność na stronie, lokalizację czy dane biometryczne.
[1] https://www.techtimes.com/articles/236067/20181208/simulated-captcha-solver-proves-this-web-security-feature-will-soon-be-unreliable.htm


